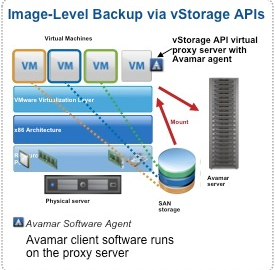
I’m going back over some of the new differences in Avamar 6.1 and am very impressed with the enhancements that Avamar now has with VMware image based backups. Before version 6.1 you needed a seperate image proxy for Linux and a seperate proxy for Windows, now with the new proxy design both Operating Systems have been integrated into one proxy. Not only does the proxy support both OS’s but now it also supports File Level Recovery to both OS’s where as Windows was only supported previously. To be more specific; the Unified Proxy now supports Windows NTFS, and Linux ext2, ext3, and LVM. The proxy does NOT support the following: Windows GPT Partitions, Windows Dynamic disks, Extended Partitions, Encypted Partitions, Compressed Partitions, or XFS. (more…)
Tag: emc
-

EMC ICSEA Isilon Certified
Posting up the next certification as I’m now completed with 2 of 3 of my goal for the month. Didnt seem like there was too much difference on the training between the ICSEA and the ICSA, but I’m going to assume the technical certifications will be much different. I’m not one to hang up physical certificates on my wall in my home office, so I decided to make a certifications page on my blog so I can visually keep track of all of them. It will take me awhile to dig up all of the other certifications but I’ll go ahead and start with the Isilon certs.
(more…) -
Warning 6698 VSS exception code 0x800706be thrown freezing volumes – The remote procedure call failed
When you try to create shadow copies on large volumes that have a small cluster size (less than 4 kilobytes), or if you take snapshots of several very large volumes at the same time, the VSS software provider may use a larger paged pool memory allocation during the shadow copy creation than is required. If there is not sufficient paged pool memory available for the allocation, the shadow copy cannot complete and may cause the loss of all previous shadow copy tasks. Follow this article and apply the fix:
-
EMC VNXe Data Protection with Symantec Backup Exec
EMC recently launched their new VNX storage line which is a unified storage platform with one management framework supporting file, block, and object optimized for virtual applications. From that line they also produced a more affordable “VNXe” model for small business and remote offices. There are a number of ways to protect the VNXe including snapshots, replication and NDMP backups. Typically I would use a couple different combinations of these three technologies depending on the business need and data risk, but today I am only going to go into detail with backing up the VNXe using Backup Exec as it is the most popular choice for small and medium businesses which is fitting for the VNXe.
(more…) -
Unable to Connect to the OpenStorage Device
Error:
Unable to connect to the OpenStorage device. Ensure that the network is properly configured between the device and the media server.Environment:
Backup Server: Symantec Backup Exec 2010 R3
OpenStorage Device: DataDomain DD670 running 5.0.0.7-226726Today I was configuring DDBOOST for Backup Exec 2010 R3 using a replicated pair of DD670’s. The DD670’s were pre-configured with version 4.9 which I upgraded to 5.0.0.7-226726. I setup the 670 with a standard configuration and then configured a storageunit. (more…)
-
Troubleshooting: A checkpoint validation (hfscheck) of server checkpoint data is overdue.
Event ID: 114113
Description:
Checkpoint validations (hfschecks) of server Checkpoints are performed to ensure that checkpoints are valid for disaster recovery needs. A regularly scheduled hfscheck did not take place as scheduled. If hfschecks are not being performed disaster recovery may not be possible.Remedy:
Check to make sure that checkpoint is configured and enable it if it’s not. Check to make sure checkpoint validation is configured and enable it if it’s not. If checkpoint and validation are enabled and schedule and either no checkpoint was taken or no validation occurred, contact your support center. -
How to check node capactiy across an EMC Avamar grid
I recently came across an issue where the avamar garbage collect was not running. When I run a status.dpn on the grid I get the following message for the garbage collect status:
Last GC: finished Wed Aug 25 01:01:04 2010 after 00m 50s >> recovered 0.00 KB (MSG_ERR_DISKFULL)
The total grid utilization is currently at 87% and I also saw some Unacknowledged Events with the following information:
Code: 4202 Message: failed garbage collection with error MSG_ERR_DISKFULL
This error is a direct result of the garbage collect run limit being reached or exceeded due to excessive checkpoint overhead. To verify and check all of the node capacities use the following commands; also if this is a single node you will not have to use the mapall command.
su – admin
ssh-agent bash
ssh-add ~admin/.ssh/admin_key
Enter the passphrase for the admin keys. (If you dont know what it is then you should not be doing this) Then run:
mapall –noerror ‘df -h’
This should give you the filesystem for each node including the sizes, used, and space available. Then run:
avmaint nodelist | grep percent-full
This will give you a cleaner output of the numbers that really matter. Pay attention to each node’s “abs-percent-full”
In most cases you should contact EMC support to resolve this issue, however in some cases running an HFS check or checkpoint validation on your oldest checkpoint might free up enough overhead to get you back on track. -
Avamar Agent now standard on Iomega ix-12 array
EMC Avamar agents are usually not found running directly on storage arrays, until now. At EMC world Iomega gave a sneak preview into its ix12 array with a built in Avamar agent. The Avamar agent will allow for SMB remote offices to utilize Avamar’s deduplication features without requiring additional hardware. (more…)
-
Hello BURA world!
This is my first blog post, just breaking this thing in! You will see more Backup Recovery and Archiving posts as I get rolling !